Stenocomplete Released
Now that I’m slowly progressing towards words that are more complex than “tab sap cap pat”, a fast lookup tool would be helpful. For this, the first address that came up was StenoTray. Reading from the Plover log, it suggests dictionary entries that start with the current stroke. Trying for around half an hour, I was not able to start it properly. It only showed a white screen, even after pointing to the correct config and log files. At some point I just hard-coded the dictionary paths into the Java code to make it work. While writing this post, I found a StenoTray fork which might fix the configuration.
Yet, even after it worked, there were a number of things that I didn’t like too much. Being a beginner, I wanted to have a tool that also allows QWERTY input for word suggestions. Since StenoTray reads from the Plover log file, it only listens to Plover. Another requirement was fingerspelling. Finally, the white background as well as the font and text coloring were not for me.
So I decided to write my own program which is called stenocomplete (based on the word autocomplete). The first naming idea was stenodict but that’s already a thing.
Even though I’m more proficient in Java, I decided to write it in Python. The main reason is that Plover is written in Python and maybe I’d like to add stenocomplete as a Plover plugin at some point.
Also, I didn’t want to program a GUI because I don’t want to take care of the color and font configuration to make it fit to the rest of my system.
Thereby, I simply output the suggestions to a terminal window using the standard Python 3 print() method together with some UNIX specific commands for clearing the terminal screen and hiding the cursor.
This is how it looks like on my system after typing steno:
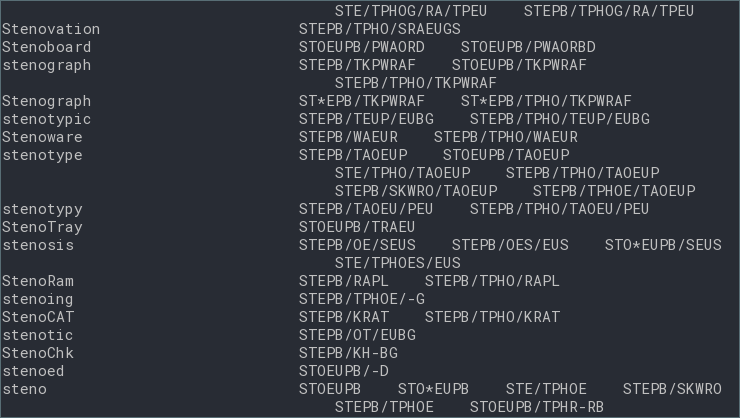
In order to listen to QWERTY and Plover outputs at the same time, I use python-xlib together with pyxhook from pykeylogger to log the keyboard input.
The code for this is relatively compact so you can review it yourself since key-logging is a delicate topic.
Since I’m using the terminal for the output and python-xlib for the logging, my code currently only works on Linux systems.
I didn’t try to run it on a Mac since I don’t own one so it would be interesting if someone with a Mac could give it a try.
Stenocomplete will certainly not work on a Windows system.
I tried to separate the Linux-specific code from the rest to allow Windows support at some point.
If you are interested in a Windows version of stenocomplete, let me know.
But enough about the implementation details.
Here’s how stenocomplete (on the left) looks like in comparison to StenoTray (on the right) after writing AEUR:
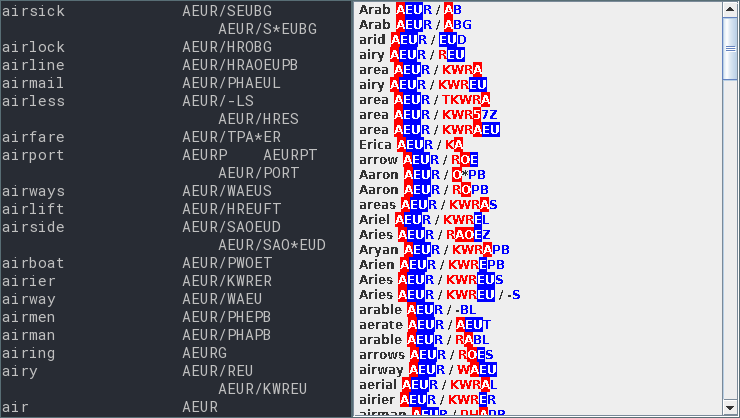
Besides the obvious color and font differences, you may notice that StenoTray displays the shortest completions on the top while stenocomplete lists them on the bottom.
There are two reasons for this.
One reason is that, when printing to the terminal, it is difficult to jump back to the beginning of the input if the input is longer than the window size.
I couldn’t find a way to scroll up or down without using libraries such as curses.
Luckily, I prefer to have the shortest completions on the bottom of the window.
If you would strongly prefer to have them on the top, let me know.
Another difference is that in StenoTray, multiple possible strokes for a word are displayed separately while stenocomplete displays them together in one row.
To be fair: The font in StenoTray does not always look this bad.
On macOS, it looks like this.
Finally, there’s a large gap between translation and strokes in stenocomplete because strokes are aligned horizontally and there are some more completions of air when scrolling up, the longest being air conditioning.
{kind=link}
Important features for me are fingerspelling and the handling of dictionary entries that contain multiple words.
Here’s an example where I entered the strokes -T/P*:

StenoTray only handles one stroke at a time and in this case suggests dictionary entries that start with the P* stroke.
While the direction from fingerspelling (or typing on a QWERTY keyboard) to strokes is already usable, the stroke completion needs some more work.
For example, writing the stroke TPHAOU results in only one suggestion in stenocomplete which is knew, the direct translation of the stroke.
StenoTray on the other hand shows many suggestions:

This is because StenoTray completes the stroke itself while stenocomplete only works with the translation. A solution for this is based on an idea that Lars Doucet discussed in his steno diary. The letters that Plover outputs as part of a translation appear almost at the same time and far more quickly than it is humanly possible when fingerspelling or typing with QWERTY. This way, stroke translations can be detected and a translation-to-stroke dictionary can answer which stroke was typed. Yet, this will not be completely trivial since stroke translations also heavily depend on the previous strokes. I will work on this in the coming days.
If you want to try out stenocomplete, you can follow the instructions in the GitHub repository. I would be happy to hear from you if you have any feedback!